اولین دیتابیس توزیع شده ای که با آن کار کردم CSPIT نام داشت. پروژه بوسیله یک معمار خبره رهبری می شد و چند نفر از باهوش ترین برنامه نویسانی که در آمازون می شناختم در آن بودند.
CSPIT هرگز رنگ آفتاب را ندید. در قسمت تکنیکی، به دو دلیل ما دچار مشکلات مقیاس پذیری (scalability) بودیم. در این مقاله، هدف من به اشتراک گذاری آن دو گلوگاهی است که برای ما توسعه دهندگان برای یادگرفتن آنها سالها زمان صرف شد. البته، صرف دانستن اینها برای ساختن یک پایگاه داده توزیع شده کافی نیست، اما یقینا نکات زیادی در آنها وجود دارد که زمان قابل ملاحظه ای از شما در ساخت سیستمهای توزیع شده صرفه جویی خواهد شد.
اولین تجربه ما درباره یک فهم تئوریک از اینکه چه محاسباتی به راحتی قابل گسترش (scale) هستند، می باشد. یک قدم به عقب برمیگردیم: شما میتوانید تمام مسائل سیستمهای توزیع شده را به یکی از دو روش زیر حل کنید (ما فعلا فقط همین دوتا را بلدیم):
- آماده کردن دیتا برای محاسبات
- آماده کردن محاسبات برای دیتا
به عنوان مثال، فرض کنید که داده های فروش خود را در یک پایگاه داده توزیع شده ذخیره میکنید و میخواهید درآمد کل خود را محاسبه نمایید. می توانید به این سوال ساده با یکی از دو روش یاد شده عمل کنید. من سوال را با اس کیو ال شرح می دهم، اما ایده کلی برای هر زبان کوئری یکسان می باشد.
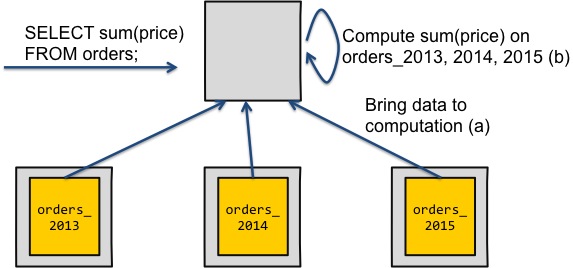
دیتاگرام اول این امیتاز سادگی را دارد. میتوانید هر محاسباتی را با آوردن داده ها به یک نود خاص و سپس اجرای کوئری اصلی روی داده ها شرح دهید. البته، عیب این روش در عدم مقیاس پذیری آن است. اولا شما تعداد زیادی ورودی/خروجی شبکه در هر نقل و انتقال داده دارید و شبکه منبع با کمترین قابلیت مقیاس پذیری شماست. دوما شما هیچ موازی سازی در این کار انجام نداده اید و تمام محاسبات را دیک ند انجام داده اید.
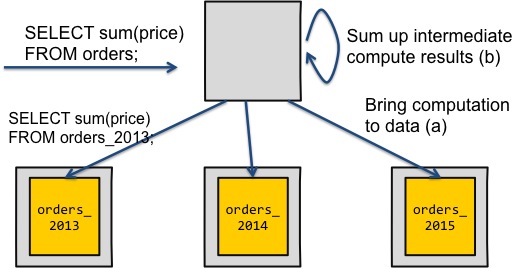
دیاگرام دوم دو مشکل عدم گسترش را حل میکند. در اینجا ما هم در حال موازی سازی محاسبات هستیم و هم فقط نتایج محاسبات را درشبکه انتقال میدهیم. البته ما باید محاسبات نهایی را در نود هماهنگ کننده انجام دهیم، ولی این محاسبات بسیار ساده است.
حال، اجازه دهید به یک محاسبات پیچیده تر بپردازیم. فرض کنید می خواهیم میانگین ارزش سفارشات را محاسبه کنیم. در این مورد، آیا میتوانیم از هر نود بخواهیم که میانگین خودش را محاسبه کند، و سپس ما از آنها میانگین بگیریم؟
نه. ما نمیتوانیم از میانگین نودهای دیگر میانگین بگیریم. باید هر نود محاسباتی مجموع مقادیر خودش به همراه تعداد آنها را محاسبه کند و سپس میانگین از مجموع مقادیر کل نودها تقسیم بر مجموع تعداد ارقام کل نودها، در نود اصلی محاسبه شود. این یک انتقال ساده است، اما چرا باید آن را حالا انجام داده ایم؟
به عبارت دیگر، چرا موازی سازی کوئری جمع از کوئری میانگین ساده تر است؟ زیرا عمل جمع در ذات خود تعویض پذیر است، در حالیکه میانگین نه. (a+b=b+a; a/b<>b/a)
وقتی محاسبات خود را به سمت داده ها می برید، در واقع محاسبات را به حالت تعویض پذیرشان انتقال میدهید. خوب، این نکته چگونه به من کمک میکند که دیتابیس توزیع شده بسازم؟
اگر در حال ساخت یک دیتابیس هستید، احتمالا یک زبان کوئری که هر پرس و جو را بصورت یک فرم منطقی شرح میدهد دارید. صفت تعویض پذیری در هرزبان خوب تعریف شده ای بکار می آید. در زیر، من اس کیو ال را به عنوان زبان مثال انتخاب میکنم، به دو دلیل: SQL دارای تطبیق پذیری بالایی است و دلیل دوم اینکه ما در Citus تجربه مقیاس پذیری با آن را داریم.
اس کیو ال از جبر رابطه ای برای شرح یک کوئری استفاده میکند. وقتی یک کوئری را به پایگاه داده خود میفرستید، کوئری شما تجزیه شده و به یک درخت منطقی تبدیل میشود. برای مثال اگر کوئری شما شامل عبارت WHERE باشد، در درخت کوئری شما بصورت یک نود فیلتر است. اگر کوئری شما یک تابع جمع داشته باشد، بوسیله یک نود عملگر شاخه دار درخت توصیف میشود.
نگاشت از SQL به جبر رابطه ای و عملگرهای جبر رابطه ای بحث مفصل و با جزئیاتی است. بنابراین ما در اینجا میخواهیم وارد آن جزئیات شویم و در عوض بر نحوه استفاده از این عملگرهای جبری در مبحث سیستمهای توزیع شده متمرکز میشویم. اجازه دهید با یک کوئری اس کیو ال به عنوان مثال شروع کنیم.
SELECT sum(price) FROM orders, nation WHERE orders.nation = nation.name AND orders.date >= '2012-01-01' AND nation.region = 'Asia';
این کوئری جدول فروش را با جدول کوچک ملیت ادغام میکند تا ردیفهایی که یک دارای شرط خاصی هستند انتخاب نماید. کوئری سپس حجم کل فروش را در ردیفهای انتخابی محاسبه میکند. اجازه دهید به پلن توزیع منطقی کوئری نگاهی بیاندازیم.
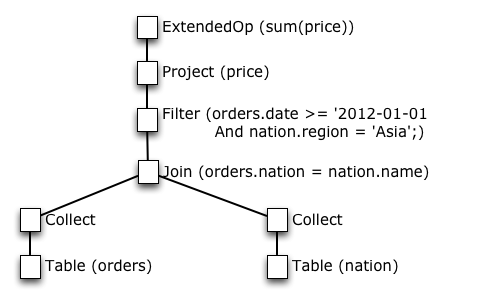
در اولین نگاه، این درخت کوئری شبیه یک درخت جبر رابطه ای استاندارد است. هرچند اگر نگاهی دقیق تر بیاندازید یک تفاوت مشاهده خواهید کرد. درخت کوئری دو نود Collect در برگهایش دارد. این نوع جدید عملگر داده های تحت خود را برای ارائه به یک ماشین منفرد جمع آوری میکند.
اگر به ابتدای این مقاله برگردیم، این نودهای کالکت داده های دو جدول در یک مکان جمع میکنند. بقیه درخت کوئری، عملیات Join, filter و محاسبات روی داده های جمع آوری شده را انجام میدهد.
اما در حال حاضر میدانیم که مقیاس پذیر نیست. اجازه دهید که اکنون دانش خود در مقیاس پذیری شبکه، عملگرهای تعویض پذیر و جبر رابطه ای را باهم بکار بگیریم. آیا عملگر collect با عملگر filter قابل جابجایی می باشد؟ بله. چقدر خوب! پس اجازه دهید Collect را بالا بکشیم.
در حقیقت، یک راه ساده برای بهینه کردن پلن منطقی وجود دارد: نودهای Collect را بالا بکشید و ندهای محاسبات را پایین، تا زمانی که ویژگیهای جابجایی و پخش پذیری حفظ شوند. شکل زیر پلن منطقی را بعد از بهینه سازی نشان میدهد.
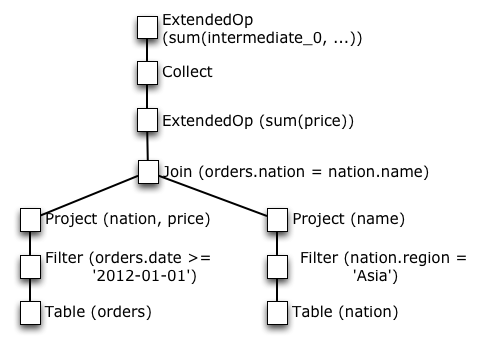
این پلن بهینه شده بسیاری از محاسبات را پایین کشیده و مقدار خیلی کمی از داده را جمع آوری میکند. این باعث مقیاس پذیری میشود. البته بسیار مهمتر از آن، این پلن منطقی اینکه چگونه عملگرهای جبر رابطه ای در سیستمهای توزیع شده مقیاس پذیر میشوند را فرمالیزه میکند.
خب این نکته کلید اول در ساختن دیتابیسهای توزیع شده بود. در سرزمین سیستمهای توزیع شده تعویض پذیری پادشاه است. کوئری های خود را با احترام به پادشاه مدل کنید و آنها مقیاس پذیر خواهند شد.
در مقاله ای دیگر دومین کلید برای توزیع پذیری دیتابیس را شرح خواهم داد.
