این مقاله به بررسی تکنیکی نحوه پخش داده های ما بر روی تعداد زیادی پایگاه داده MySQL SERVER میپردازد. ما این روش تکه تکه کردن را در اوایل سال 2012 اجرا کردیم و هنوز سیستمهای ما از آن برای ذخیره کردن داده های اصلی ما استفاده میکنند.
قبل از اینکه به نحوه تکه تکه کردن داده هایمان بحث کنیم اجازه دهید کمی در مورد ماهیت داده هایمان صحبت کنیم.
Pinterest یک موتور اکتشاف برای علایق شماست. از دیدگاه داده محور Pinterest بزرگترین گراف انسانی تولیده شده از علایق است. بیش از 50 بیلیون پین که توسط کاربران بر روی بیش از یک بیلیون برد ایجاد شده اند. افراد معمولا پین های دیگران را پین مجدد یا لایک میکنند، پین ها، بردها و یا علایق دیگران را دنبال میکنند و یا صفحه فید پین کننده های دیگر را دنبال میکنند. عالیه! اما خب این همه داده چگونه در مقیاس بالا مدیریت میشود؟
پین ها در حال زیاد شدن
بر اساس تخمینهایی که در سال 2011 زده شد ما در حال رشد بیشتر از هر استارتاپ دیگری بودیم. حوالی سپتامبر 2011 تقریبا هر قسمت از ساختار ما در حال سرریز ظرفیت بود. ما چند نوع تکنولوژی NoSQL داشتیم که سرانجام هر کدام از هم فروپاشید. همچنین تعداد انبوهی سرور slave مای اسکیوال داشتیم که برای read ها استفاده میشد که تعداد زیادی باگ تولید میکرد به خصوص در رابطه با caching. بنابراین تمام مدل ذخیره داده خود را دوباره معماری کردیم. برای اینکه موثر واقع شود نیازمندیهای خود رامستند کردیم.
نیازمندیها
- کلیت سیستم می بایست بسیار پایدار،دارای عملکرد راحت و قابل گسترش تا ماه باشد! میخواستیم سیستم از یک مجموعه کوچک از باکسها تا تعداد زیادی از باکسها در زمان گسترش سیستم قابل مقیاس پذیری باشد.
- تمام محتوای تولید شده توسط پین کننده ها باید در هرزمانی قابل دسترسی باشد
- سیستم می بایست از پرس و جوی تعداد زیادی پین ها در یک برد در یک ترتیب مشخص پشتیبانی بکند. ( مثل زمان ایجاد یا ترتیب مشخص شده توسط کاربر)
- برای سادگی آپدیتها همیشه بهترین تلاش خواهند بود. برای رسیدن به ثبات بیشتر ابزارهای دیگری نیز نیاز خواهد بود مانند یک سیستم لاگ تراکنش توزیع شده. اینها جالب هستند و لی نه زیاد راحت!
فلسفه طراحی و نکات
از آنجا که میخواستیم داده هایمان در چندین دیتابیس پخش شوند، نمیتوانستیم از join ها، کلیدهای خارجی و یا ایندکسها برای جمع کردن همه داده ها استفاده کنیم، بنابراین از آنها فقط میتوانستیم در زیر کوئریهایی که در همه دیتابیسها نیستند استفاده کنیم.
همچنین ما load balancing در داده هایمان نیاز داشتیم. ما از جابجایی داده ها متنفریم، بخصوص از جابجاییهای مورد به مورد، زیرا منشا خطا هستند و سیستم را بدون اینکه نیازی باشد پیچیده میکند. اگر مجبور شویم داده ها را جابجا کنیم بهتر است که کل نود ویرچوال به یک نود فیزیکی دیگر جابجا شود.
برای اینکه پیاده سازی سیستم زودتر به نتیجه برسد، نیاز داشتیم که راحت ترین راه حل قابل استفاده و نودهای بسیار پایدار در پلتفرم خود داشته باشیم.
تمام داده ها باید به ماشینهای slave برای پشتیبانگیری کپی شوند. همچنین باید دارای دسترس پذیری بالا باشند. در نسخه اجرایی نرم افزار ما فقط سرورهای master کارخواهیم کرد. هرگز در نسخه در حال کار نرم افزار از سرورهای slave استفاده نمیکنیم. سرورهای ثانویه ایجاد lag میکنند که باعث باگهای عجیب میشوند. وقتی که داده های شما تقسیم شد دیگر نمیتوان برای تراکنش با سرورهای slave امتیازی قایل شد.
و در آخر به یک روش خوب برای ایجاد آی دیهای عمومی یکتا (UUID) برای تمام آبجکتهای موجود نیازمندیم.
چگونه تکه تکه شدیم!
چیزی که ما در حال ساخت آن بودیم باید دارای بازده، پایدار و قابل اتکا میبود. به عبارت دیگر باید گیر نمیکرد و به همین دلیل ما تصمیم گرفتیم از یک تکنلوژی بالغ که بیس کارمان نیز برپایه آن بود یعنی MySQL استفاده کنیم. ما از دست تکنولوژیهای جدیدتر با مقیاسپذیری اتوماتیک مانند MongoDB، Cassandra و Membase فرار کردیم، زیرا به اندازه کافی بالغ نشده بودند و با روشی که ما از آنها استفاده میکردیم کرش میکردند!
نکته جانبی: هنوز هم به استارتاپها پیشنهاد میکنم که از چیزهای جدید چشم پوشی کنند و فقط از MySQL استفاده کنند. به من اعتماد کنید. من زخمهایی دارم که حرفم را ثابت مکینند!
مای اسکیوال یک تکنولوژی بالغ و پایدار است و خوب کار میکند. نه تنها ما از آن استفاده میکنیم بلکه کمپانی های با مقیاس بزرگتر از ما نیز از آن استفاده میکنند. مای اسکیول از نیاز ما برای پرس و جوی داده ها، انتخاب رنج خاصی از داده ها و تراکنشهای روی ردیفهای داده ها پشتیبانی میکنند. داشتن ویژگیهای بیشتر یک جهنم است، چون ما به آنها نیازی نداریم. اما در هر حال مای اسکیو ال یک را حل تک باکس است، بنابراین ما نیاز داریم که داده هایمان را تکه تکه کنیم. و این راه حل ماست:
ما از هشت سرور EC2 که هر کدام یک نمونه مای اسکیو ال را اجرا میکنند شروع کردیم:
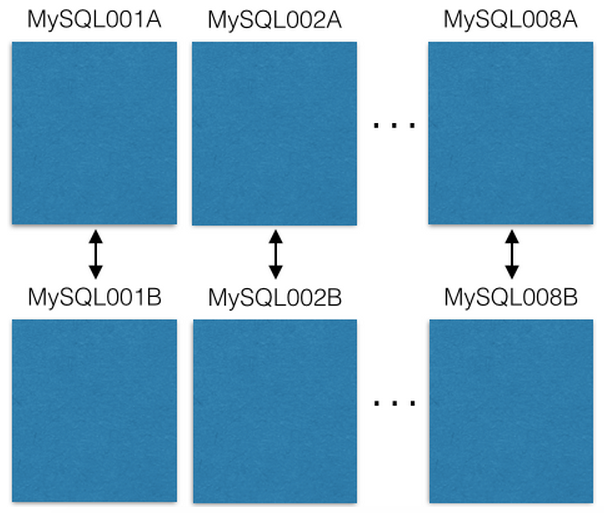
هر سرور مای اسکیوال یک master-master است که بر روی هاست پشتیبانگیری کپی شده تا در زمان از کار افتادن سرور اولیه استفاده شود. سرورهای در حال کار ما فقط بر روی master میخوانند و مینویسند. من هم همان را پیشنهاد میکنم. این کار همه چیز را ساده میکند و از باگهای کپی داده ها جلوگیری میکند.
Each MySQL instance can have multiple databases:
هر نمونه MySQL میتواند چند دیتابیس داشته باشد:
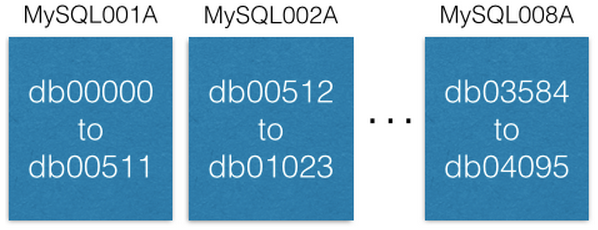
دقت کنید که چگونه هر دیتابیس را بصورت یکتا بنامهای db00000، db00001 تا dbNNNNN نامگذاری کرده ایم. هر دیتابیس یک تکه از داده ماست. در هنگام طراحی این تصمیمی گرفته شده که که هر جزیی از داده که در یک تکه قرار میگیرد، هرگز به بیرون آن تکه منتقل نخواهد شد. هر چند ممکن است با جابجا کردن خود تکه ها به ماشینهای دیگر به ظرفیت آنها اضافه کنیم.
ما جدولی از تنظیمات ساختیم که به ما میگوید هر تکه در کدام ماشین قرار دارد:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]این تنظیمات فقط هنگامی تغییر میکنند که نیاز باشد یک تکه را جابجا کنیم یا یک هاست را جایگزین نماییم. اگر یک master از کار بیفتد، میتوانیم از slave استفاده کنیم و یک slave جدید استفاده نماییم. تنظیمات در یک ZooKeeper ذخیره شده و در هنگام آپدیت به سرویسهایی که تکه های MySQLرا نگهداری میکنند ارسال میشود.
هر تکه شامل مجموعه مشابهی از جداول می باشد: pins, user_has_pins, users_likes_pins, pin_liked_by_user و غیره.
خب حالا چطور داده ها را در این تکه ها تقسیم کردیم؟
ما یک آی دی 64 بیتی ایجاد کردیم که شامل آی دی تکه، نوع داده و محل ذخیره سازی داده در جدول ( آی دی محلی ) میشود. ای دی تکه 16 بیتی، آی دی نوع داده 10 بیتی و آی دی محلی 36 بیتی است. دوستان حرفه ای ما شاید دقت کرده باشند که مجموع ارقام ذکر شده 62 بیت است. تجربیات گذشته من در طراحی کامپایلر به من آموخت که بیتهای رزرو ارزش خود را در لحظات طلایی نشان میدهند. پس ما 2 بیت صفر نیز داریم.
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)با فرض اینکه پین مورد نظر https://www.pinterest.com/pin/241294492511762325 باشد اجازه دهید پین آی دی 241294492511762325 را تشریح کنیم:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429
Type ID = (241294492511762325 >> 36) & 0x3FF = 1
Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733پس این آبجکت در تکه 3429 زندگی میکند. نوع آن از نوع داده 1 است و در ردیف 7075733 در جدول pins قرار دارد. برای مثال فرض کنید که این تکه در سرور MySQL012A قرار دارد. ما میتوانیم بدین صورت به آن دسترسی پیدا کنیم:
conn = MySQLdb.connect(host=”MySQL012A”)
conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)دو نوع از داده ها وجود دارند: آبجکت ها و نگاشتها. آبجکتها شامل جزییاتی مانند اطلاعات پین ها میشوند.
جداول آبجکتها
جداول آبجکتها ماند pins, users, boards و comments یک آی دی ( همان آی دی لوکال که کلید اولیه افزایشی می باشد) و یک آبجکت blob شامل داده های آبجت با فرمت json م یباشند.
CREATE TABLE pins (
local_id INT PRIMARY KEY AUTO_INCREMENT,
data TEXT,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;برای مثال کی آبجکت پین به شکل زیر خواهد بود:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}برای ایجاد یک پین جدید، تمام داده ها را جمع میکنیم و یک آبجکت json میسازیم. سپس در مورد آی دی تکه تصمیم میگیریم ( البته ترجیح میدهیم که از همان آی دی تکه ای استفاده کنیم که برد مربوطه در آن قرار دارد ولی نه لزوما). برای پینها نوع داده 1 است. به دیتابیس متصل میشویم و یک آبجکت json در جدول pins درج میکنیم. MySQL در پاسخ به ما آی دی محلی افزایشی را برمیگرداند. حالا که آی دی تکه، نوع و لوکال را داریم میتوانیم یک آی دی کامل 64 بیتی را بسازیم.
برای ویرایش یک پین ما با استفاده از یک ترانزاکشن MySQL آبجکت JSON را میخوانیم، ویرایش میکنیم و سپس مینویسیم.
> BEGIN
> SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE
[Modify the json blob]
> UPDATE db03429.pins SET blob=’<modified blob>’ WHERE local_id=7075733
> COMMITبرای حذف یک پین میتوانید ردیف آن را در MySQL حذف کنید. هر چند بهتر است که یک فیلد به آبجکت JSON با نام active اضافه کنید و مقدار آن را با flalse ست نمایید و سپس نتایج ی که به کلاینت ارایه میشود را بر اساس آن فیلتر کنید.
جداول نگاشت!
یک جدول نگاشت یک آبجکت را به آبجت دیگر متصل میکند، مثلا یک برد را به پین موجود در آن. یک جدول MySQL برای نگاشت شامل سه ستون میشود. یک آی دی 64 بیتی برای آی دی منبع، یک آی دی 64 بیتی برای مقصد و یک آی دی ترتیب.CREATE TABLE board_has_pins (
board_id INT,
pin_id INT,
sequence INT,
INDEX(board_id, pin_id, sequence)
) ENGINE=InnoDB;جداول نگاشت یکطرفه هستند، مثل board_has_pins. اگر به جهت برعکس آن نیاز داشته باشید باید جدول دیگری مثل pin_owned_by_board ایجاد کنید. ای دی ترتیب به ما یک ترتیب میدهد. ما معمولا پین های جدید را در بردهای جدید با ای دی ترتیب unix timesamp وارد میکنیم. ترتیب میتواند هر عددی باشد، اما استفاده از unix timestamp باعث میشود که همیشه چیزهای جدید اولیت بیشتری داشته باشند. شما میتوانید در جداول نگاشت مثل مثال زیر جستجو کنید:
SELECT pin_id FROM board_has_pins
WHERE board_id=241294561224164665 ORDER BY sequence
LIMIT 50 OFFSET 150این مثال به شما تا 50 pin_id را میدهد که میتوانید برای جستجوی آبجکتهای پین استفاده کنید.
آنچه که ما انجام دادیم در واقع استفاده از join ها در لایه برنامه است. یک ویژگی خوب استفاده از join در لایه برنامه این است که میتوانید آبجکت ها را جدای از نگاشتها کش کنید. ما کش pin_id>pin_object را در یک کلاستر memcache نگهداشتیم اما board_id>pin_ids را در یک کلاستر redis. این به ما اجازه میدهد که تکنولوژی مناسب برای آبجکتی که میخواهیم کش کنیم انتخاب نماییم.
افزایش ظرفیت
در سیستم ما سه راه اولیه برای افزایش ظرفیت بیشتر وجود دارد. راحت ترین راه آپگرید کردن ماشینهاست.
راه بعدی استفاده از رنجهای جدید است. در ابتدا ما فقط 4096 ایجاد کردیم زیرا ای دی تکه های ما 16 بیتی بود. آبجکتهای جدید فقط میتوانستند در 4k تکه ابتدایی ایجاد شوند. در نقطه ای، ما تصمیم گرفتیم که سرورهای جدید MySQL با تکه های 4096 تا 8191 را ایجاد نماییم.
راه آخر افزودن ظرفیت انتقال تکه ها به ماشین های جدید است. اگر بخواهیم ظرفیت بیشتری به MySQL001A که تکه های 0 تا 511 را در خود دارد اضافه کنیم، یک جفت master-master جدید با بزرگترین نام بعدی اضافه میکنیم و MySQL001A را روی آن کپی میکنیم.
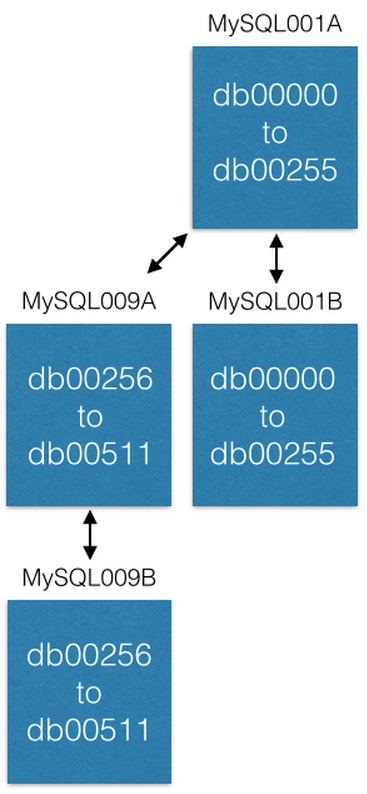
وقتی کپی تمام شد، تنظیمات خود را تغییر میدهیم تا MySQL001A فقط تکه های 0 تا 255 را داشته باشد و MySQL009A فقط تکه های 256 تا 511
چند ویژگی عالی
برای آنهایی که سیستمهایی برای تولید UUID های جدید میخواهند، میفهمید که ما آنها را در این سیستم رایگان گذاشته ایم! وقتی یک آبجکت جدید ایجاد میکنید و آن را در جدول آبجکت وارد میکنید، یک آی دی local به شما برمیگرداند. این آی دی محلی در ترکیب با آی دیک تکه و آی دی نوع به شما یک UUID میدهد.
برای شما که از ALTER ها برای افزودن ستونها به جداول MySQL استفاده میکنید، میدانید که آنها خیلی کند و دردسر بزرگی هستند. روش ما نیازی به ALTER های مای اسکیوال ندارد. در Pinterest ما فقط یک ALTER در سه سال آخر داشتیم. برای اضافه کردن فیلدهای جدید به آبجکتها، بسادگی به سرویسهای یاد بدهید که اسکیمای JSON شما فیلدهای جدیدی دارد. شما میتوانید مقادیر پیش فرض داشته باشید که وقتی آبجکت JSON را deserial میکنید و فیلد جدید شما را ندارد از مقادیر پیشفرض استفاده شود. اگر به جداول نگاشت نیاز دارید، جداول جدید ایجاد کنید و هر وقت احساس کردید آنها را آپ کنید. وقتی کارتان تمام شد محصوص خود را پرتاب کنید!
تکه های mod
برخی از آبجکتهای باید با غیر آی دی ها جستجو شوند. برای مثال اگر یک پین کننده با اکانت فیسبوک خود لاگین کند، ما به یک نگاشت از آی دی فیسبوک به آی دی Pinterest نیازمندیم. آی دیهای فیسبوک برای ما فقط چند بیت هستند بنابراین آنها را در یک سیستم تکه جداگانه با نام تکه mod ذخیره میکنیم.
تکه های mod خیلی شبیه سیستم تقسیم بندی که در بخش قبل توضیح دادیم هستند، ولی شما میتوانید در آنها با ورودی متفرقه جستجو کنید. این ورودی هش میشود و سپس در مقابل تعداد کل تکه های موجود در سیستم مانده گیری میشود. نتیجه حاصل تکه ای است که اطلاعات در آن خواهد بود. برای مثال :
shard = md5(“1.2.3.4") % 4096در این مورد شماره تکه 1524 خواهد بود. یک فایل کانفیگ مشابه برای آی دی تکه نگه خواهیم داشت:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”},
{“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”},
{“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”},
…]پس برای یافتن داده ها در مورد آی پی 1.2.3.4 باید این کار را انجام دهیم:
conn = MySQLdb.connect(host=”msdb003a”)
conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)برخی از ویژگیهای عالی ای دی تکه را از دست داده ای مثل محلی بودن خاص. شما باید با تکه هایی که همگی در ابتدا ساخته شده اند شروع کنید. همیشه بهترین کار این است که آبجکت ها را در سیستم خود با آی دیهای غیر قابل تغییر ارایه دهید. این کار باعث میشود که مجبور نشوید تعداد زیادی رفرنس را وقتی که کاربر usernameخود را عوض میکند تغییر دهید.
نظرات پایانی
این سیستم 3.5 سال است که در Pinterest استفاده میشود و بنظر میرسد که همیشه آنجا باشد. پیاده سازی آن کاملا مستقیم و برگرداندن داده ها از ماشینهای قدیم بسیار ساده است. اگر شما یک استارتاپ هستید که با دردسرهای فزاینده مواجه هستید و بتازگی تکه جدید خود را ساخته اید، ساخت یک خوشه از ماشینهای پردازشی پس زمینه برای انتقال اطلاعات از ماشینهای قدیمی به تکه های جدید خود مدنظر قرار دهید. من گارانتی میکنم که داده ها از بین خواهند رفت هر چقدر هم که شما سخت تلاش کنید. بنابراین فرآیند انتقال داده ها را چندین بار تکرار کنید تا چیزهایی که باید کپی شوند به صفر یا مقدار بسیار کمی برسند.
این سیستم بهترین تلاش ماست. اما در کل به ما atomicity ، isolation و جامعیت را نمیدهد! اما نگران نباشید. شما بدون این تضامین هم احتمالا خوب خواهید بود. شما همه این لایه ها را اگر لازم شد میتوانید در پروسسها و سیستمهای دیگر ایجاد کنید، اما من به شما میگویم چیزی که در حال حاضر بصورت رایگان بدست می آورید این است: همه چیز خوب کار میکند. قابلیت اتکای بالا و سادگی و سرعت بالای آن. اگر شما در مورد A,I و C نگران هستید برای من بنویسید. من میتوانم به شما در مورد این موضوعات کمک کنم.
و اما در مورد failover. چی؟ ما سرویسی ساخته ایم که تکه های MySQL را نگه میدارد. ما یک جدول تنظیمات تکه ها را در ZooKeeper ذخیره کرده ایم. وقتی یک سرور maser از کار می افتد، ما اسکریپتهایی داریم که slave را به کار میگیرد و آنگاه سرور جایگزین را آماده میکنیم. حتی امروز ما از auto-failover استفاده نمیکنیم.

 صابر
صابر